.png)
Think about the last time a customer contacted your support team with a question they had asked before.
Your agent searched for the answer. Maybe they found it quickly. Maybe they asked a more senior colleague. Maybe they pieced together something from three different sources and hoped it was still accurate.
That moment, multiplied across every agent, every shift, every customer interaction, is where support organisations quietly lose control of quality, speed, and consistency.
The knowledge already exists inside your business. That is rarely the problem. The problem is that it is buried.

Support teams are sitting on a wealth of knowledge. Product manuals, onboarding guides, policy PDFs, how-to videos, demo recordings, knowledge base articles, past support conversations, and years of ticket history. Somewhere in that content is often the exact answer a customer needs right now.
The problem is that finding it quickly isn't always easy.
So instead of resolving queries quickly, agents do what any reasonable person does when information is hard to find. They search. They ask someone. They approximate. They re-answer questions that have already been answered dozens of times before, just never written down in a place that is easy to reach.
The visible consequence is slower response times. The less visible consequence is something more damaging: inconsistency.
When different agents reach the same answer by different routes - or worse, reach different answers entirely - customer experience becomes unpredictable. And unpredictable support erodes trust faster than almost anything else.
The pressure does not stay confined to individual agents either. It migrates upward. Senior staff become the default answer to every difficult question, regardless of whether they are the right person to ask. Their time gets consumed by queries that existing documentation should already address. And the cycle continues.
This is knowledge friction. And most organisations have far more of it than they realise.
The standard response to this problem has been to build a knowledge base. Create a repository. Write it all down. Teach people where to look.
It sounds sensible. In practice, it rarely works as intended.
Knowledge bases go out of date quickly. The people responsible for updating them are usually the same senior staff already stretched thin by day-to-day demand. Content accumulates without structure. Agents learn, by experience, that the knowledge base is not always reliable, so they stop consulting it and return to asking colleagues instead.
The knowledge base becomes a place where answers go to age rather than a tool that actively helps people work.
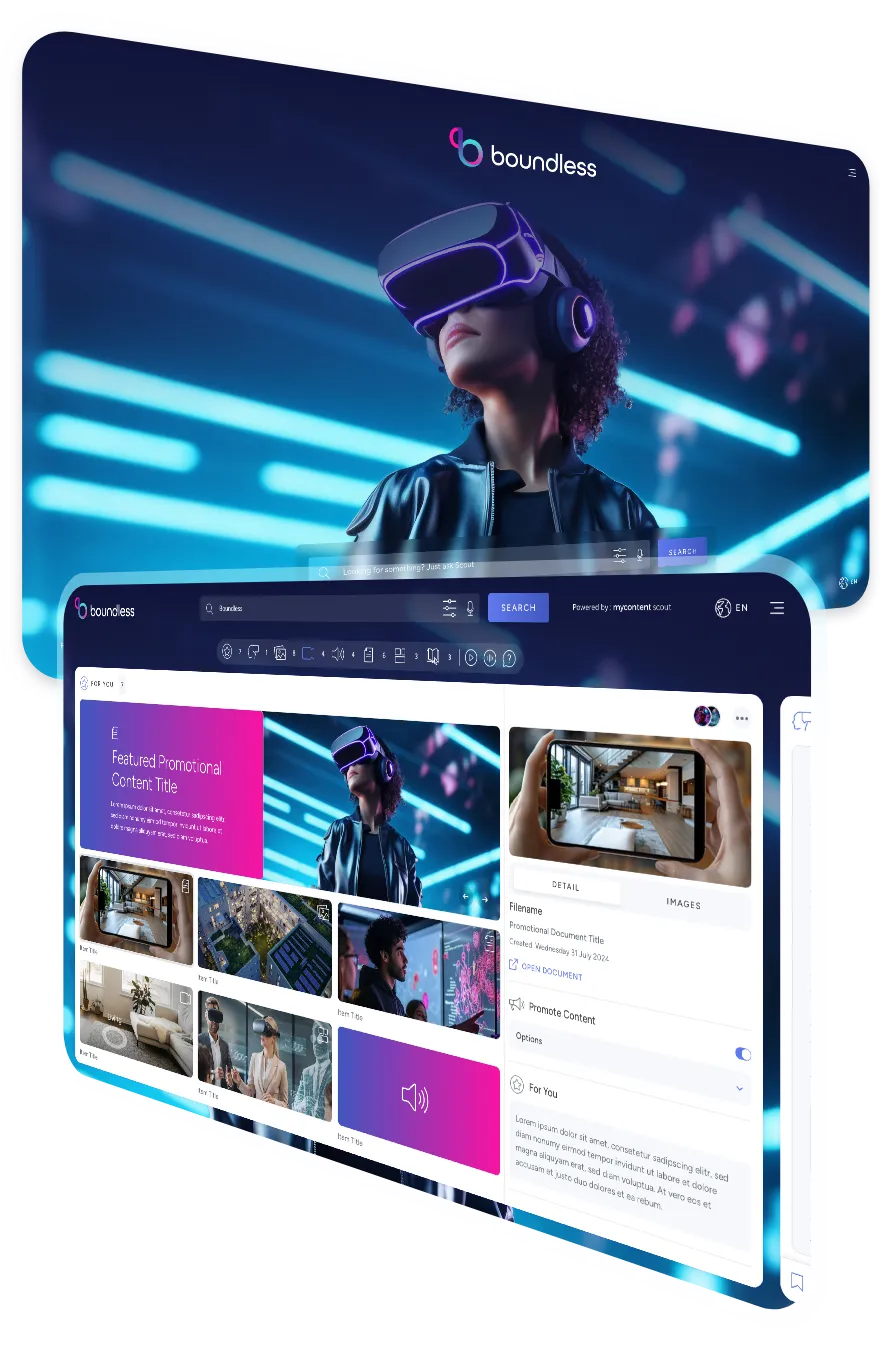
The deeper issue is that traditional search was never designed for how people actually think. An agent dealing with an upset customer does not search for a document title. They search the way anyone does: in natural language, based on the problem in front of them. Keyword-based retrieval systems were not built for that. They surface documents. They do not surface answers.

The shift that AI-powered knowledge systems make is not about adding more content. It is about making existing content useful in the moment it is needed.
When a support agent asks "what is our refund policy for orders placed during a promotional period?", a well-implemented AI knowledge system does not return a list of documents to sift through. It understands the intent behind the question, searches across every relevant source, policy documents, ticket histories, training materials, internal guides, and surfaces a direct, cited answer.
That distinction matters enormously in a support context.
The difference between finding a document and finding an answer is measured in minutes per ticket. Across a team handling hundreds of interactions daily, those minutes become hours. Those hours become capacity, consistency, and cost.
Faster resolution times. When agents can surface accurate answers in seconds rather than minutes, the entire support operation moves faster. Queues shorten. Customer wait times fall. First-contact resolution rates improve.
Consistent answers across the team. When every agent draws from the same intelligent source rather than their individual experience, the quality of responses stops varying by who happens to be on shift. A customer asking the same question on Monday and Friday gets the same answer, regardless of who handles it.
Reduced pressure on experienced staff. When institutional knowledge is accessible to everyone through the system, senior agents stop being the bottleneck. Their expertise is encoded and available, not locked inside their heads and rationed through interruption.
Confidence for every agent. New starters are often the most exposed to knowledge gaps. When the system can surface relevant information regardless of how long someone has been in the role, the ramp-up time compresses significantly, and the risk of incorrect information being passed to customers reduces with it.
Organisations with sensitive content, customer data, legal documentation, internal policies with restricted access, often pause here.
The question is legitimate: if an AI system is drawing from everything, how do you ensure that agents only see what they are supposed to see?
The answer is that a well-built knowledge platform does not ignore permissions, it enforces them. Access controls determine what each user or team can query. An agent in general customer support asking a question will only receive answers drawn from content they are authorised to see. Restricted content remains restricted. Sensitive documents do not surface to people who should not have access to them.
This means the security model of your existing content library does not need to be abandoned. It needs to be reflected intelligently in the knowledge system built on top of it.
For organisations operating under compliance frameworks, or handling customer data subject to regulatory requirements, this is not a minor consideration. It is a prerequisite for adoption. The right platform treats secure knowledge access as a feature, not an afterthought.
There is a particular challenge with evaluating knowledge management platforms: generic demonstrations do not tell you much.
A sales demo built around example content is not the same as your team searching across your actual policies, your actual documentation, and your actual ticket history. The value only becomes visible when the system is working with the content that matters to you.
This is why a free trial with real content upload capability is worth taking seriously. The question is not whether AI-powered knowledge search works in principle. The evidence on that is substantial. The question is whether it works for your content, your team structure, and your specific support workflow.
Thirty days, with enough content to reflect how your organisation actually operates, answers that question in a way no demonstration can.
Customer support has always been a knowledge problem dressed up as a service problem.
When agents struggle, it is rarely because they lack the desire to help. It is because the information they need is not accessible in the form they need it, at the speed the situation requires. The result looks like a service failure from the outside. From the inside, it is a knowledge infrastructure failure.
AI-powered knowledge systems do not replace the human judgement, empathy, and relationship skills that define exceptional support. They remove the friction that prevents those qualities from being expressed consistently.
When an agent is not spending three minutes searching for a policy and two minutes asking a colleague, they are spending five extra minutes actually helping the customer in front of them.
That is the shift. Not more documents. Faster answers.
The organisations that gain the most from AI knowledge systems are rarely the ones with the best-organised content libraries. They are the ones willing to start with what they have.
Your existing documents, however scattered, contain the institutional knowledge your team needs. The question is not whether you can build a perfect knowledge base before implementation. The question is whether the system is intelligent enough to make imperfect, real-world content useful.
If your support team is spending time searching instead of solving, the content is almost certainly already there. It just needs to be accessible.
Start your free 30-day trial with MyContentScout and see what your team can find.





Get in touch with our team to arrange a demo of MyContentScout and see how it could transform your workflow with AI search, content analysis and categorisation, saving you time and providing smart insights from various sources.